Einleitung
Dieses Projekt ist Teil meiner Masterarbeit. Ziel der Untersuchung war es, die Möglichkeiten der akustischen Qualitätsüberwachung bei der automatisierten Steckverbinder-Montage zu bewerten. Sie vergleicht potenzielle Sensortechnologien und untersucht, ob eine zuverlässige Qualitätssicherung durch den Einsatz von maschinellem Lernen erreicht werden kann. Aufgrund fehlender öffentlicher Datensätze wurde ein eigener Datensatz erstellt, der 2064 von einem Industrieroboter ausgeführte Steckversuche sowie 37 Minuten Aufnahmen impulsartiger Geräusche enthält.
Es wurden fünf Algorithmen zur Impulserkennung untersucht, von denen vier Erkennungsraten von über 99 % erreichten. Durch den Einsatz von Data-Augmentation-Techniken entstanden anschließend neun Datensätze mit unterschiedlichen Störgeräuschkonfigurationen, die für das Training und die Evaluierung von Convolutional Neural Networks (CNNs) verwendet wurden. Zunächst erfolgte ein Vergleich der Modelle, die mit einzelnen Merkmalen optimiert wurden. Die leistungsstärksten Merkmale (MFCC, Log-Mel-Spektrogramm und Delta-Log-Mel-Spektrogramm) wurden daraufhin in multimodalen Modellen kombiniert. Auf dem Datensatz ohne Störgeräusche konnte dabei eine Genauigkeit (Accuracy) von 98,90 % erzielt werden; selbst bei starken Störgeräuschen (SNR = –10 dB) wurde noch eine Genauigkeit von 95,39 % erreicht. In der Validierung erreichte das Klassifizierungsmodell schließlich eine Genauigkeit von 99,04 %, bei lediglich fünf Fehlklassifikationen von insgesamt 522 Steckversuchen.
Die Ergebnisse zeigen, dass der Einsatz von Beschleunigungssensoren und ein multimodaler Ansatz die Klassifizierungsgenauigkeit signifikant verbessern und die Empfindlichkeit gegenüber impulsartigen Störgeräuschen stark verringern können. Das beste Klassifizierungsergebnis ergab sich aus der Kombination von MFCC-Merkmalen, die aus den Signalen zweier Achsen des dreiachsigen Beschleunigungssensors extrahiert wurden.
Sound Event Detection
Ein System zur Erkennung akustischer Ereignisse (Sound Event Detection, SED) ist eine Technologie zur automatischen Identifizierung und Klassifizierung spezifischer Geräusche innerhalb einer akustischen Umgebung. Ein besonderer Anwendungsfall ist die Erkennung und Klassifizierung impulsartiger Geräusche, die sich durch ihre sehr kurze Dauer, einen abrupten Beginn sowie eine hohe Energiekonzentration in einem kurzen Zeitintervall auszeichnen. Das beim automatisierten Stecken eines Verbinders entstehende ‚Klick‘ erfüllt diese Merkmale eindeutig.
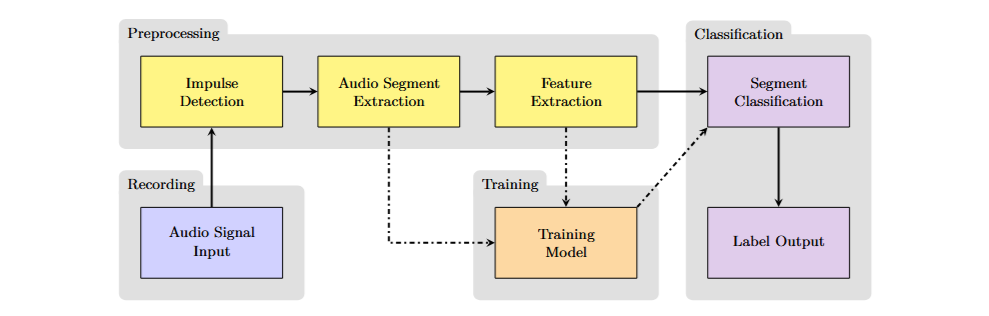
Ein typisches System zur Erkennung impulsartiger Geräusche basiert auf dem in der oberen Abbildung dargestellten kaskadierten Ansatz. Ein Impulserkennungsalgorithmus analysiert das Signal in Echtzeit, um die Zeitpunkte kurzzeitiger, energieintensiver Ereignisse zu identifizieren. Wird ein Impuls detektiert, so wird ein kurzer Signalabschnitt um das Ereignis herum extrahiert. Aufgrund der hohen Auflösung ist das Rohsignal jedoch ungeeignet, direkt als Eingabe für ein Klassifizierungsmodell verwendet zu werden. Deshalb werden Merkmale (Features) aus dem Rohsignal extrahiert, die dessen Eigenschaften kompakter und zugleich repräsentativer abbilden. Zu den am häufigsten verwendeten Merkmalen zählen verschiedene Varianten von Spektrogrammen (z. B. Log-Mel, Delta-Log-Mel) sowie die Mel-Frequency Cepstral Coefficients (MFCC). Im Rahmen dieses Projektes wurden zudem drei Merkmale im Zeitbereich berücksichtigt. Abschließend werden die aus dem Signalabschnitt extrahierten Merkmale in vordefinierte Kategorien klassifiziert. Für diesen Schritt haben sich in früheren Untersuchungen Convolutional Neural Networks als besonders leistungsfähig erwiesen.
Datensatzerstellung
Für die akustische Qualitätsüberwachung beim automatisierten Steckprozess unter Verwendung von Vibrationssensoren existieren keine geeigneten öffentlichen Datensätze. Daher wurde ein eigener Datensatz erstellt. Er umfasst insgesamt Aufnahmen von 2064 Steckversuchen, die von einem Industrieroboter durchgeführt wurden, einschließlich sowohl erfolgreicher als auch fehlgeschlagener Versuche.
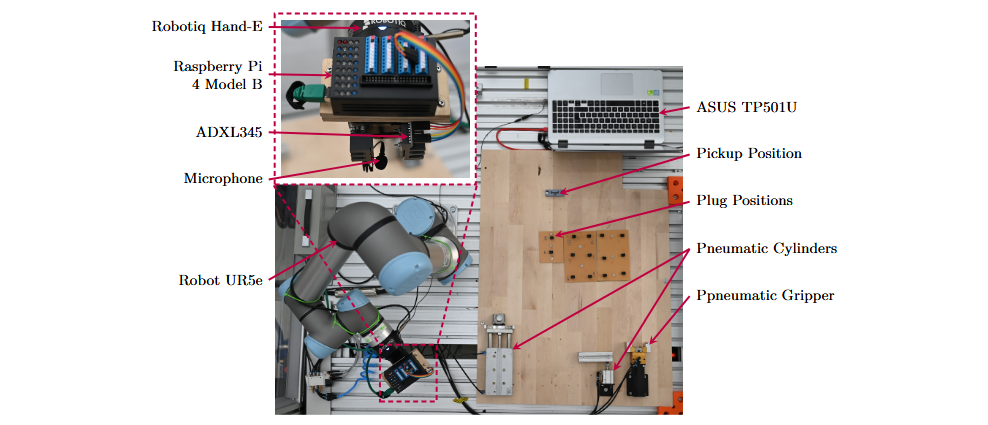
Die Steckversuche wurden mit einem kollaborativen Roboter vom Typ Universal Robots UR5 durchgeführt. Als Endeffektor kam der adaptive Greifer Robotiq Hand-E zum Einsatz. Die Greiferbacken wurden speziell für den verwendeten Steckverbinder (Hirose DF51K) entwickelt und mittels Stereolithographie gefertigt. Für die Datenerfassung wurden ein Mikrofon (Rode Lavalier GO) und ein dreiachsiger Beschleunigungsaufnehmer (Adafruit ADXL345) verwendet. Bei jedem Steckversuch nahm der Roboter einen DF51K-Stecker auf und setzte ihn in der entsprechenden Buchse ein. Um die Variabilität der Aufnahmen zu erhöhen, kamen insgesamt 58 Stecker und 29 Buchsen zum Einsatz.
Impulsartige Störgeräusche wurden durch Schläge auf die Grundplatte mit verschiedenen Objekten sowie durch drei pneumatische Aktuatoren erzeugt. Die Aktuatoren wurden dabei zufällig und unabhängig voneinander betrieben. Insgesamt wurden 37 Minuten dieser Geräusche aufgezeichnet.
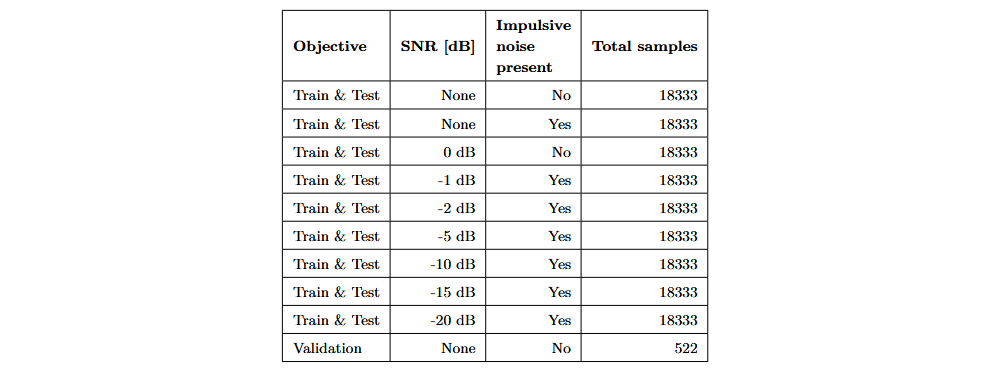
Um die Robustheit der Klassifizierungsmodelle gegenüber Hintergrundgeräuschen zu erhöhen, wurden Data-Augmentation-Techniken wie Zeitverschiebung und das Hinzufügen von weißem Rauschen angewendet. Dadurch konnten neun augmentierte Datensätze erstellt werden, die unterschiedliche Kombinationen aus Steckgeräuschen, impulsartigem Lärm und weißem Rauschen enthalten. Diese Datensätze dienten dem Training und der Optimierung der Klassifizierungsmodelle. Die augmentierten Daten wurden in 70 % für das Training und 30 % für das Testen aufgeteilt. Zusätzlich wurden 522 weitere Steckversuche aufgenommen, um die Performance der trainierten Modelle zu validieren. Die folgende Tabelle zeigt die erstellten Datensätze:
Impulserkennung
Ein idealer Impulserkennungsalgorithmus würde die beim erfolgreichen Einstecken entstehenden Klickgeräusche zuverlässig erkennen und gleichzeitig die Erfassung irrelevanter Störgeräusche minimieren. Im Rahmen dieses Projekts wurden fünf Algorithmen zur Erkennung impulsartiger Ereignisse untersucht:
- Median Filter
Er wendet einen nichtlinearen Filter auf das Rohsignal an und erkennt einen Impuls, wenn das gefilterte Signal einen vordefinierten Schwellenwert überschreitet. - Normalised Power Sequence
Die Signalenergie wird in aufeinanderfolgenden Fenstern berechnet und normalisiert. Impulse werden durch die Auswertung der Standardabweichung innerhalb jedes Fensters erkannt, wobei eine geringe Standardabweichung auf das Auftreten eines impulsartigen Ereignisses hinweist. - Threshold on Power Sequence
Er berechnet die Signalstärke und wendet eine dynamische Schwelle an. Überschreitet die Signalstärke den Schwellenwert, wird ein Impuls erkannt. - Wrapped Linear Prediction (WLP)
Der Algorithmus verwendet ein Vorhersagemodell, das die nächsten Signalwerte auf Grundlage vergangener Abtastwerte schätzt. Impulsartige Ereignisse werden erkannt, wenn die Abweichung zwischen dem tatsächlichen und dem vorhergesagten Signal eine festgelegte Schwelle überschreitet. - Maximum RMS
Wenn der Steckvorgang automatisiert abläuft, kann die Aufnahme zu Beginn der Einführbewegung gestartet und nach Beendigung des Steckvorgangs abgeschlossen werden. Daher ist es auch möglich, das Signal erst nach Abschluss des Steckvorgangs auszuwerten. Dieser Algorithmus nimmt an, dass der Zeitpunkt mit dem maximalen RMS-Wert innerhalb der Aufnahme dem relevanten impulsartigen Ereignis entspricht.
Die Algorithmen wurden auf den Originalaufnahmen ohne Datenaugmentation angewendet. Diese Aufnahmen umfassen erfolgreiche Steckversuche, fehlgeschlagene Versuche und impulsartige Störgeräusche.
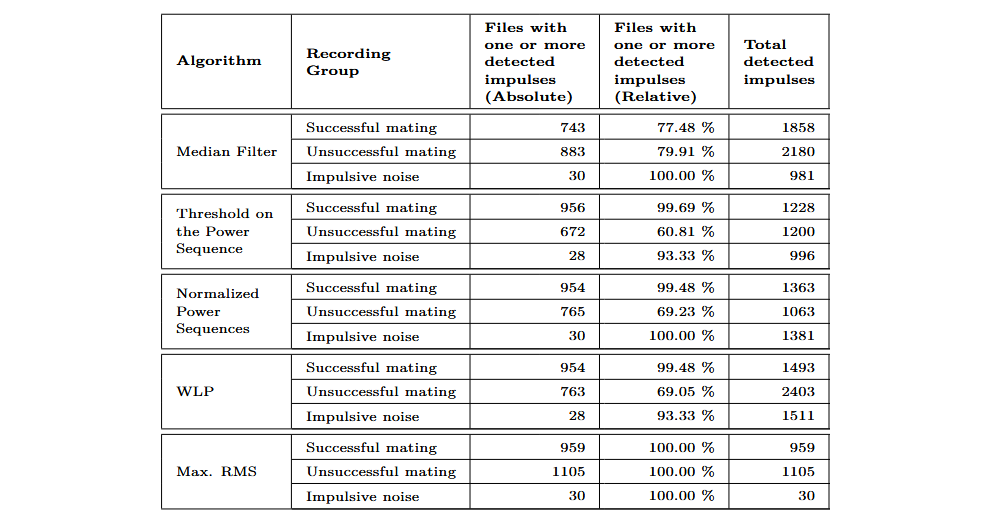
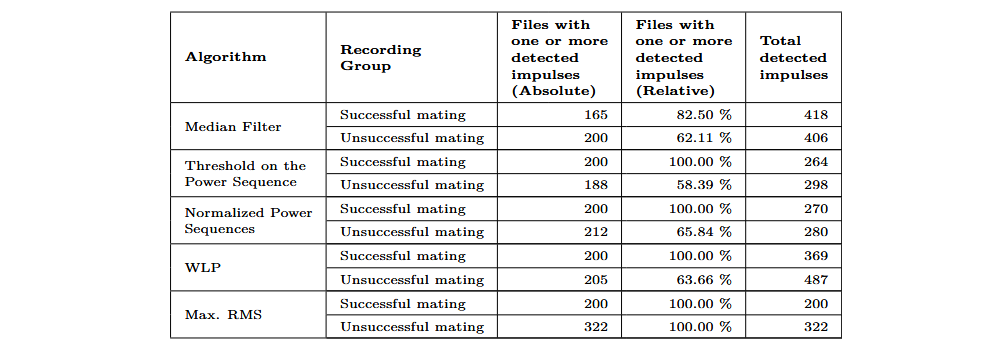
Bei der Auswertung der Ergebnisse des Maximum-RMS-Algorithmus ist zu beachten, dass er pro Aufnahme nur einen einzelnen Impuls erkennt. Wird er auf längere Aufnahmen angewendet, die impulsartige Störgeräusche enthalten, liefert er daher lediglich einen Zeitstempel. Aufgrund seines Aufbaus erreicht dieser Algorithmus eine Erkennungsrate von 100 %, solange die RMS-Werte der Hintergrundgeräusche nicht die maximalen RMS-Werte der während erfolgreicher Steckversuche erzeugten Klicks überschreiten.
Der Algorithmus mit der schlechtesten Erkennungsrate ist der Medianfilter. Er erkannte bei nur 77,48 % der Aufnahmen erfolgreicher Steckversuche einen Impuls. Die Algorithmen WLP, Threshold on Power Sequence und Normalised Power Sequence erzielten Erkennungsraten von über 99 %. Der Algorithmus Threshold on Power Sequence zeigt die geringste Empfindlichkeit gegenüber impulsartigem Lärm: Er erkannte 996 Impulse in den Aufnahmen mit impulsartigem Störgeräusch und detektierte bei 39,19 % der fehlgeschlagenen Steckversuche keinen Impuls.
Klassifizierungsmodell
Das verwendete Klassifizierungsmodell basiert auf einer multimodalen Architektur. Dabei werden die verschiedenen Merkmale parallel durch Faltungsschichten (Convolutional Layers) verarbeitet. Die von diesen Schichten extrahierten Feature-Maps werden anschließend zusammengeführt. Der resultierende Vektor wird einem Multilayer-Perzeptron (MLP) zugeführt, das die binäre Klassifikation durchführt. Das Modell ist modular aufgebaut, sodass seine Struktur an die Größe der Eingabemerkmale angepasst werden kann. Auf diese Weise können Merkmale unterschiedlicher Dimensionen und Größen von verschiedenen Sensoren kombiniert werden.
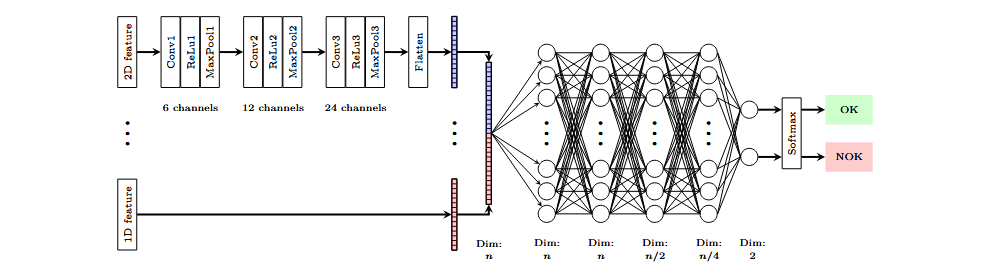
Einzelmerkmale
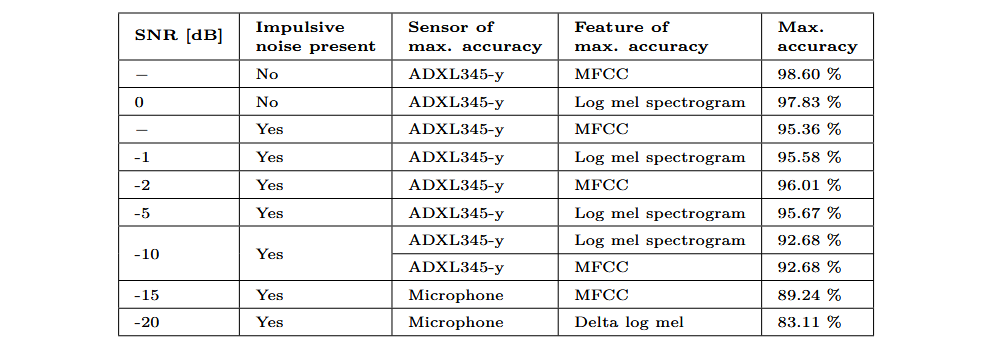
Insgesamt wurden sechs Einzelmerkmale untersucht: Log-Mel-Spektrogramm, Delta-Log-Mel-Spektrogramm, MFCC, RMS, Amplitude Envelope und Windowed Mean. Jedes Merkmal, das von einem bestimmten Sensor extrahiert wurde, diente als einziger Eingabeparameter für das oben beschriebene Klassifizierungsmodell. Die folgende Tabelle zeigt die jeweils besten Ergebnisse für jeden Datensatz sowie die jeweilige Sensor-Merkmals-Kombination, die dieses Ergebnis erzielte.
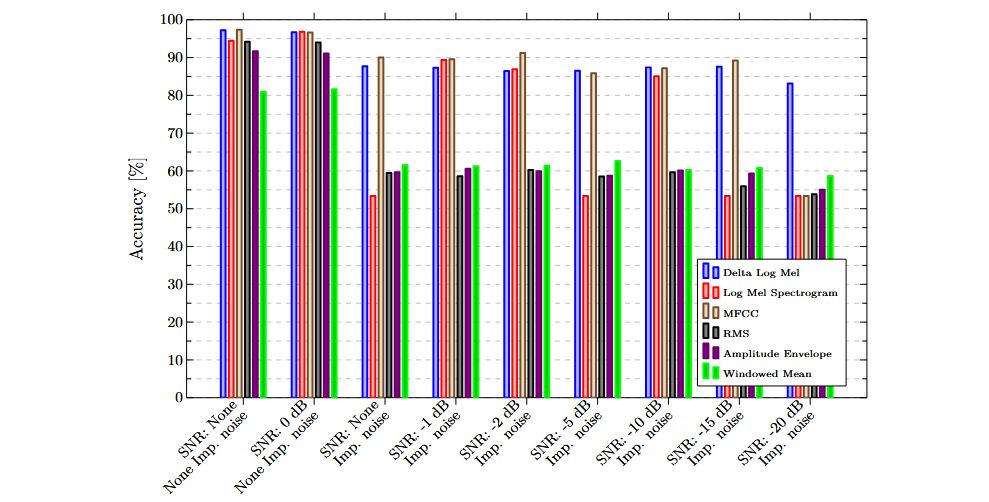
Die folgenden Diagramme zeigen die Ergebnisse, die mit einzelnen Merkmalen und Sensoren erzielt wurden. Generell schnitten frequenzbasierte Merkmale besser ab als rein zeitbasierte. Diese erreichten bei den meisten Datensätzen deutlich höhere Genauigkeiten.
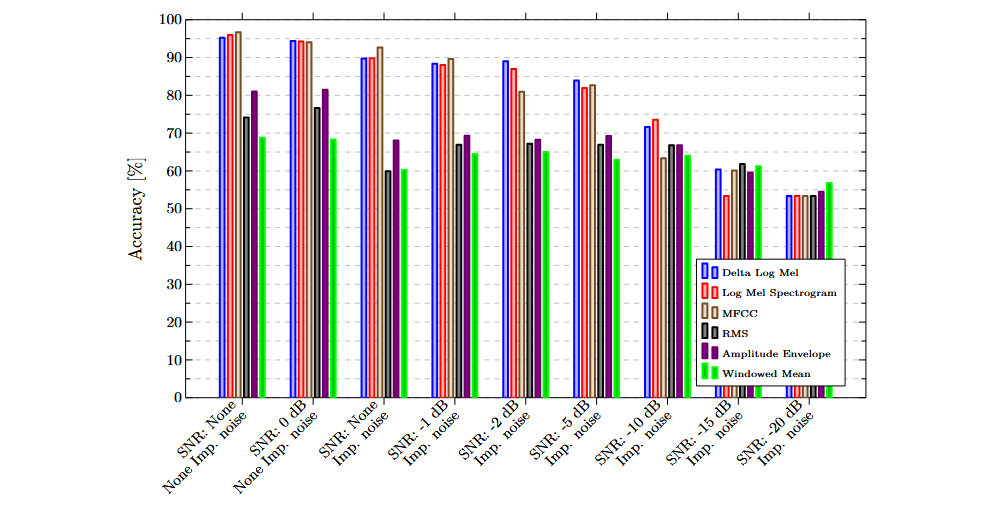
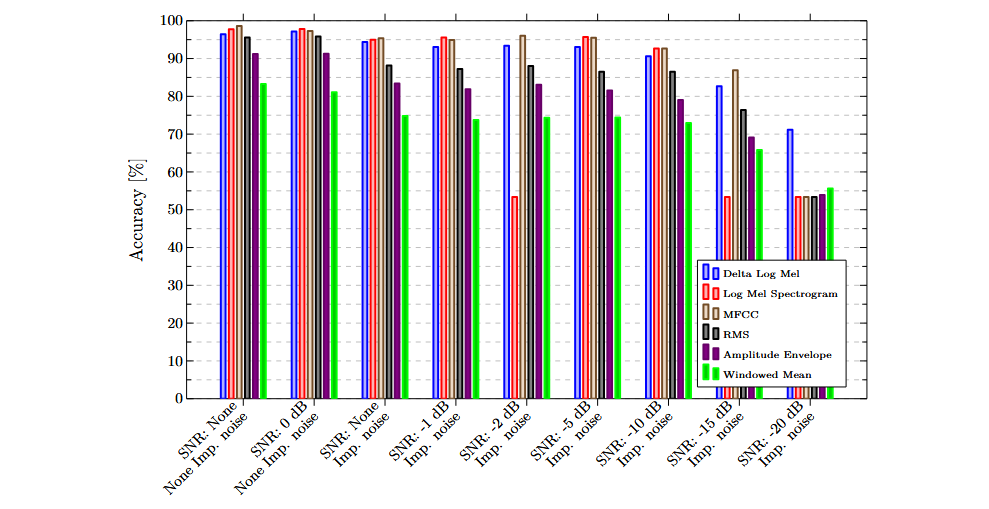
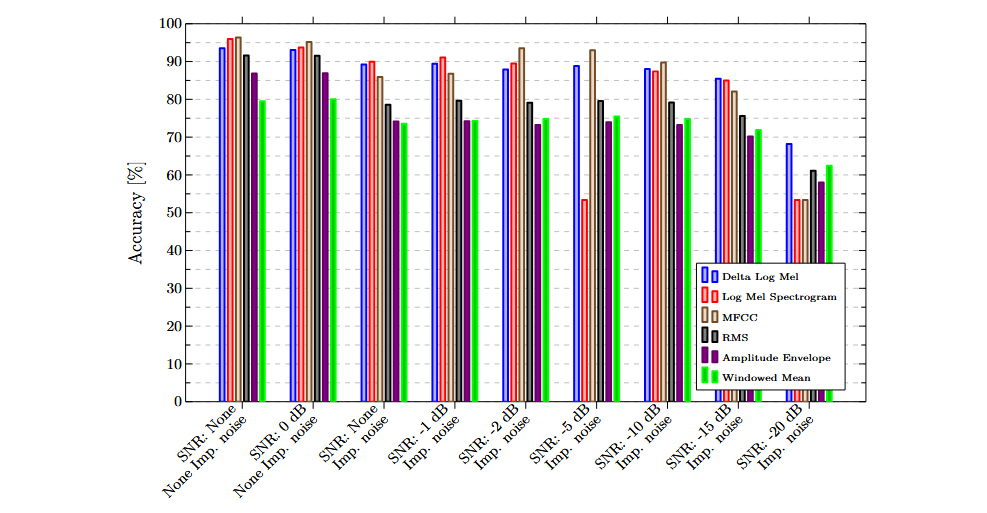
Multimodale Klassifizierung
Nach der Auswertung der Einzelmerkmale wurden Modelle untersucht, die mit Merkmalskombinationen trainiert wurden. Insgesamt wurden 14 Kombinationen ausgewählt. Die Merkmale MFCC-, Log-Mel- und Delta-Log-Mel-Spektrogramm wurden aufgrund ihrer deutlich besseren Ergebnisse in den Einzelbewertungen ausgewählt. Aufgrund der besonders hohen Leistungsfähigkeit des ADXL345-Sensors auf der y-Achse kam dieser in allen Kombinationen zum Einsatz. Die folgende Tabelle zeigt die ausgewählten Merkmalskombinationen sowie die erzielten Durchschnittsergebnisse. Die angegebenen Werte stellen die Mittelwerte über die neun betrachteten Datensätze dar.
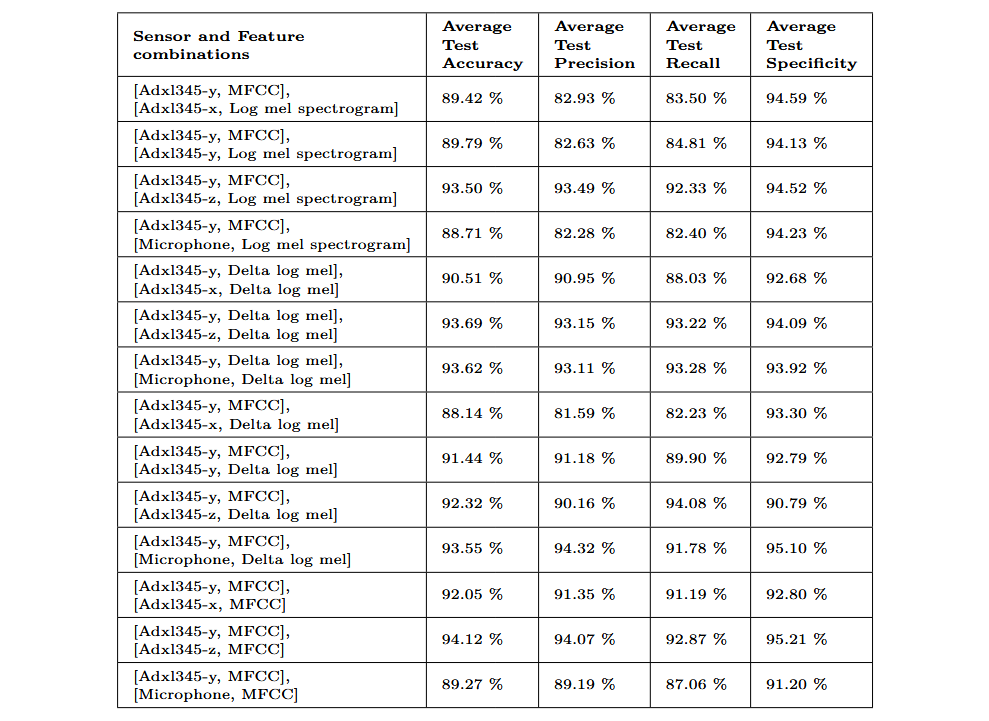
Die Kombination [[ADXL345-y, MFCC], [ADXL345-z, MFCC]] erzielte die höchsten Genauigkeits- und Spezifitätswerte. Sie ist daher die bevorzugte Merkmalskombination. Die folgende Grafik zeigt die mit dieser Kombination erzielten Ergebnisse für jeden der ausgewerteten Datensätze. Im Vergleich zu den Ergebnissen mit einem einzelnen Merkmal ist eine deutliche Verbesserung zu erkennen.
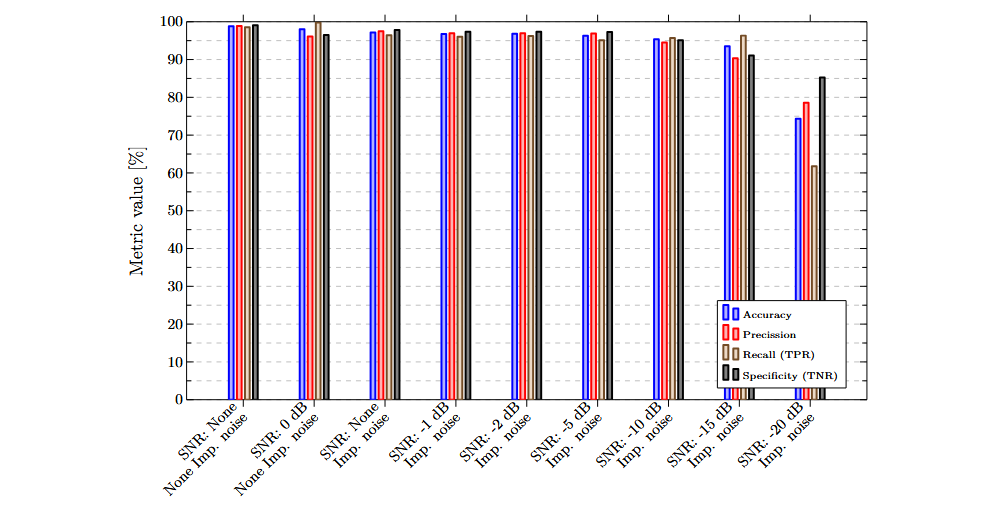
Eine geringe Empfindlichkeit gegenüber impulsartigem Lärm ist zu beobachten. Der Unterschied in der Genauigkeit zwischen dem Datensatz ohne impulsartige Störgeräusche und mit weißem Rauschen (SNR = 0 dB) sowie dem Datensatz ohne weißes Rauschen und mit impulsartigem Lärm beträgt lediglich 0,84 %. Präzision und Spezifität zeigen im Datensatz mit impulsartigem Lärm Verbesserungen von 1,35 % bzw. 1,33 %, während der Recall um 3,32 % abnimmt.
Darüber hinaus zeigen die mit dieser Merkmalskombination trainierte Modelle eine hohe Robustheit gegenüber weißem Rauschen. Für alle Datensätze mit einem Signal-Rausch-Verhältnis bis -10 dB bleibt die Genauigkeit über 95 %. Selbst bei einem SNR von -15 dB liegen alle Kennwerte weiterhin über 90 %.
Validierung
Die folgende Tabelle zeigt die Ergebnisse der fünf Impulserkennungsalgorithmen auf den Auswertungsaufnahmen. Mit Ausnahme des Medianfilters erkannten alle Algorithmen 100 % der Impulse bei erfolgreichen Steckversuchen.
Die folgende Tabelle zeigt die Validierungs-Confusion-Matrix. Das ausgewählte Modell verwendet die Merkmalskombination [[ADXL345-y, MFCC], [ADXL345-z, MFCC]]. Dieses Modell wurde mit dem Datensatz ohne weißes Rauschen und mit impulsartigem Lärm optimiert. Von den 522 Validierungsaufnahmen wurden fünf fehlklassifiziert: Zwei positive Proben wurden als negativ eingestuft, und drei negative Proben als positiv. Die daraus resultierenden Metriken sind wie folgt:
- Accuracy: 99,04 %
- Recall: 98,51 %
- Precision: 99,00 %
- Specificity: 99,38 %
