Introducción
Este proyecto corresponde a mi trabajo de fin de máster. La tesis tuvo como objetivo evaluar la viabilidad de utilizar un micrófono y un acelerómetro triaxial para detectar y clasificar las vibraciones transmitidas por estructura y por aire durante el proceso de inserción de conectores. Ante la ausencia de bases de datos públicas, elaboré un conjunto propio con 2064 intentos de inserción realizados por un robot industrial y 37 minutos de ruido impulsivo.
Evalué cinco algoritmos de detección de impulsos, todos con tasas de detección superiores al 99 %, excepto el median filter. Luego, mediante la aplicación de técnicas de aumento de datos, generé nueve conjuntos con diferentes condiciones de ruido para entrenar y optimizar redes neuronales convolucionales (CNN) usando atributos individuales. Los mejores atributos (MFCC, espectrograma log mel y espectrograma delta log mel) fueron combinados en modelos multimodales, logrando una accuracy del 98,90 % en datos sin ruido y del 95,39 % incluso con ruido blanco severo (SNR de -10 dB). En la validación, el modelo clasificador alcanzó una accuracy del 99,04 %, con solo cinco clasificaciones erróneas de 522 intentos de inserción.
Los resultados demostraron que el uso de acelerómetros y el enfoque multimodal pueden mejorar notablemente la precisión de la clasificación y reducir significativamente la sensibilidad al ruido impulsivo. El mejor resultado de clasificación se obtuvo combinando los atributos MFCC extraídos de las señales de dos ejes del acelerómetro triaxial.
Sound event detection
Un sistema de detección de eventos sonoros, o Sound Event Detection (SED), es una tecnología diseñada para identificar y clasificar automáticamente sonidos específicos dentro de un entorno acústico. Un caso particular es la detección y clasificación de sonidos impulsivos, que se caracterizan por tener una duración muy breve, un inicio abrupto y una alta concentración de energía en un corto intervalo de tiempo. El “click” generado durante la inserción automatizada de un conector cumple claramente con estas características.
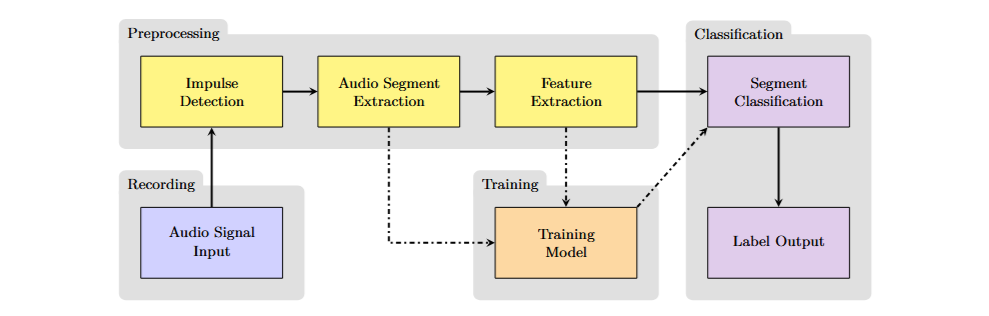
El funcionamiento típico de un sistema de detección de sonidos impulsivos sigue un flujo de procesamiento en cascada que permite aislar, analizar y clasificar únicamente los fragmentos relevantes de la señal. La señal se monitorea de forma continua, mientras un algoritmo de detección de impulsos la analiza en tiempo real para identificar los instantes en los que ocurre un evento breve y de alta energía. Para esta tarea, existe una amplia variedad de algoritmos, que se basan en la evaluación del Root Mean Square (RMS) de la señal segmentada y normalizada, así como en otros parámetros más complejos.
Cuando se detecta un impulso, se recorta un pequeño fragmento de la señal alrededor del evento. La señal en bruto tiene una alta resolución y, por lo tanto, un gran número de muestras, lo que la hace poco adecuada para ser utilizada directamente como parámetro de entrada en el modelo clasificatorio. Por ello, se extraen atributos (features) del audio en bruto que describen sus propiedades de manera más compacta y representativa. Entre los atributos más comunes se encuentran distintas variaciones de espectrogramas (log mel, delta log mel, etc.) y los Mel Frequency Cepstral Coefficients (MFCC). En este proyecto, también consideré tres atributos de dominio temporal.
Finalmente, los atributos extraídos del segmento de la señal se clasifican según categorías predefinidas. En esta etapa, las redes neuronales convolucionales, o Convolutional Neural Networks (CNN), han demostrado un alto rendimiento en investigaciones previas.
Adquisición de datos
Dado que no existen conjuntos de datos públicos adecuados para la supervisión acústica de calidad en procesos automatizados de inserción de conectores con sensores de vibración, creé un conjunto de datos propio. En total, recopilé grabaciones de 2064 intentos de inserción realizados por un robot industrial, incluyendo tanto casos exitosos como fallidos.
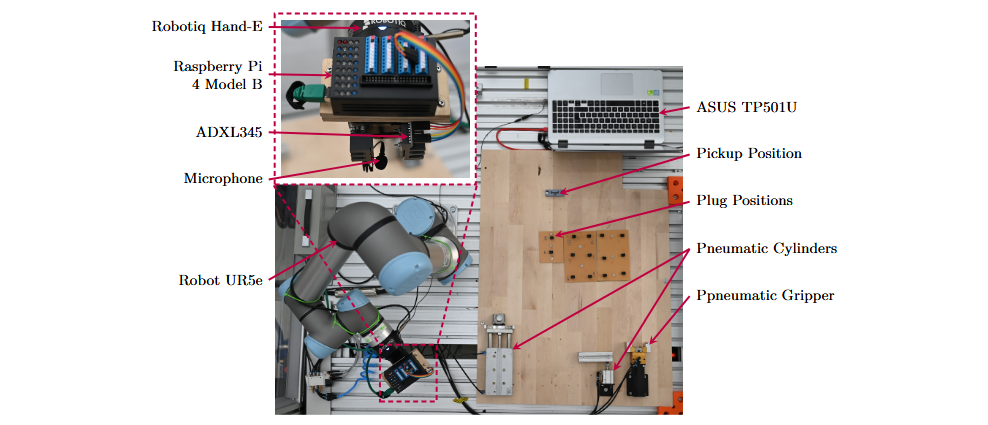
Realicé los experimentos utilizando un robot colaborativo Universal Robots UR5. El efector final empleado fue la pinza adaptativa Hand-E de Robotiq. Los dedos de la pinza fueron diseñados específicamente para el tipo de conector utilizado (Hirose DF51K) y fabricados mediante estereolitografía. Para la adquisición de datos, utilicé un micrófono Rode Lavalier GO y un acelerómetro triaxial Adafruit ADXL345. En cada intento de inserción, el robot recogía un conector macho DF51K y lo insertaba en su correspondiente conector hembra. Para aumentar la variabilidad de las grabaciones, utilicé un total de 58 conectores macho y 29 conectores hembra.
Simulé el ruido impulsivo típico de entornos industriales golpeando la base con diferentes objetos y utilizando tres actuadores neumáticos, los cuales fueron accionados de forma aleatoria e independiente. En total, registré 37 minutos de ruidos impulsivos.
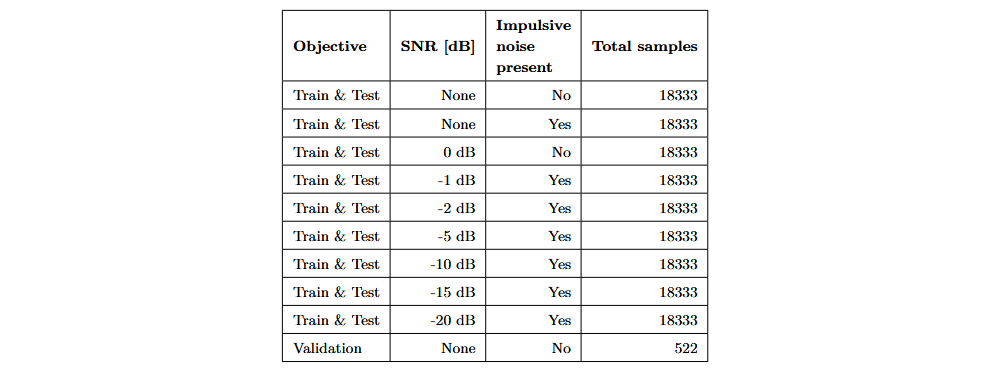
Para mejorar la robustez de los modelos de clasificación frente a ruidos de fondo, apliqué técnicas de aumento de datos, como la inserción de ruido blanco y el desplazamiento temporal. Esto permitió crear nueve conjuntos de datos aumentados, cada uno con diferentes combinaciones de sonidos y vibraciones de inserción, ruido impulsivo y ruido blanco. Estos conjuntos se utilizaron para entrenar y optimizar los modelos de clasificación. Los datos aumentados se dividieron en un 70 % para entrenamiento y un 30 % para prueba. Finalmente, grabé 522 inserciones adicionales para validar el rendimiento de los modelos entrenados. La siguiente tabla muestra los conjuntos de datos creados:
Detección de impulsos
El algoritmo ideal de detección de impulsos sería aquel que identificara con precisión los clics producidos en intentos de inserción exitosos, minimizando al mismo tiempo la detección de ruidos irrelevantes. En este proyecto evalué cinco algoritmos para la detección automática de eventos impulsivos:
- Median Filter
Aplica un filtrado no lineal sobre la señal en bruto y detecta un impulso cuando el valor filtrado supera un umbral predefinido. - Normalised Power Sequence
Calcula la energía de la señal en ventanas sucesivas, la normaliza y detecta impulsos mediante el análisis de la desviación estándar en cada ventana. Una baja desviación estándar indica la presencia de un evento impulsivo. - Threshold on Power Sequence
Basado en el cálculo de la potencia de la señal y la aplicación de un umbral dinámico. Si la potencia excede el umbral, se registra un impulso. - Wrapped Linear Prediction (WLP)
Modelo predictivo que analiza la señal mediante predicción lineal envuelta, detectando impulsos cuando la desviación entre la señal real y la predicha supera un cierto valor. - RMS máximo
Si la inserción del conector es robotizada, es posible comenzar la grabación al iniciar el movimiento de inserción y finalizarla al finalizar el movimiento. Por tanto también puede ser viable analizar la grabación tras su finalización. Este algoritmo asume que el punto con el valor máximo de RMS dentro de la grabación corresponde al evento impulsivo de relevancia.
Los algoritmos se aplicaron a las grabaciones sin aumento de datos, es decir, a las grabaciones de intentos de inserción correctos, intentos fallidos y ruido impulsivo.
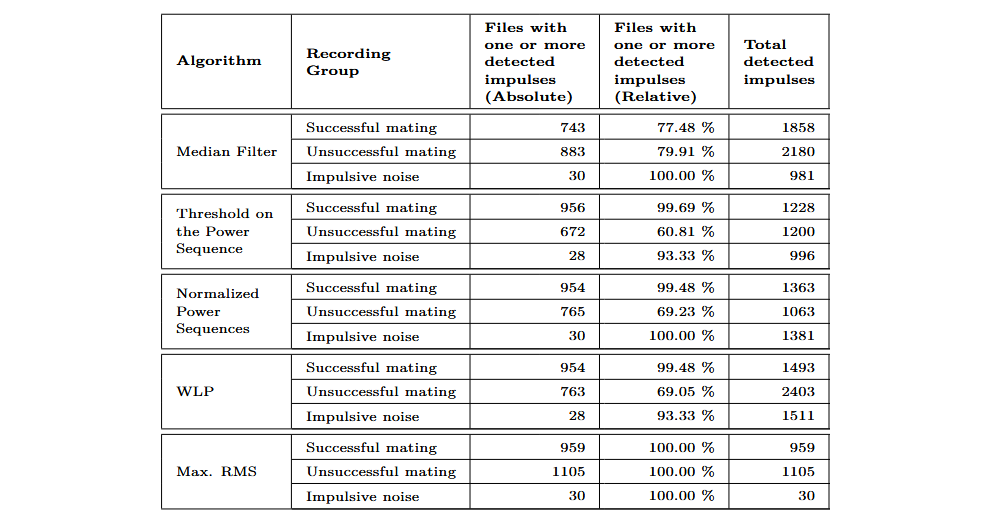
Al evaluar los resultados del algoritmo de RMS máximo, es importante señalar que este reconoce un único impulso por grabación. Por lo tanto, cuando se aplica a las grabaciones más largas que contienen ruido impulsivo de fondo, solo genera una sola marca temporal. Debido al diseño de este algoritmo, se alcanza una tasa de reconocimiento del 100 % siempre que se garantice que los valores RMS del ruido de fondo no superen los valores máximos de RMS de los clics producidos en intentos de inserción exitosos.
El algoritmo con peor rendimiento en términos de tasa de reconocimiento es el median filter, que presenta una tasa del 77,48 % en grabaciones de inserciones exitosas, un valor significativamente inferior al de los demás algoritmos comparados. Los algoritmos WLP, threshold on the power sequence y normalized power sequences muestran tasas de reconocimiento superiores al 99 %. En cuanto a la sensibilidad frente al ruido impulsivo, el algoritmo threshold on the power sequence obtuvo los mejores resultados, con 996 impulsos detectados en las grabaciones de ruido impulsivo y un 39,19 % de grabaciones de inserciones fallidas sin detección de ningún impulso.
Modelo clasificatorio
El modelo de clasificación utilizado emplea una arquitectura multimodal, en la que los atributos se procesan mediante capas convolucionales en paralelo. Los mapas de características extraídos por estas capas se concatenan, y el vector resultante se utiliza como entrada para una red MLP (multilayer perceptron) que realiza la clasificación binaria. El modelo es modular, lo que permite ajustar su estructura según el tamaño de los atributos de entrada. De esta manera, se pueden combinar atributos de diferentes dimensionalidades y tamaños, provenientes de distintos sensores, para clasificar el evento.
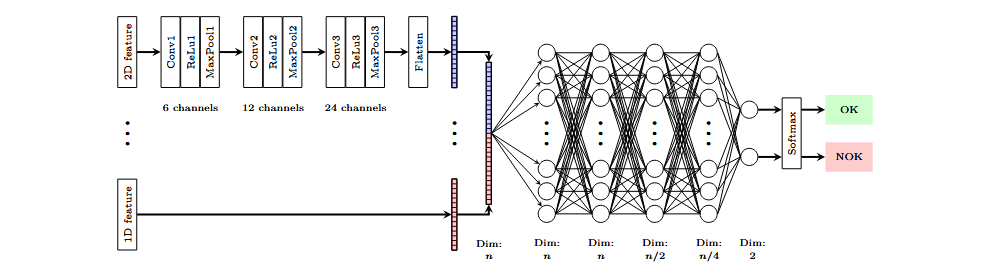
Atributos individuales
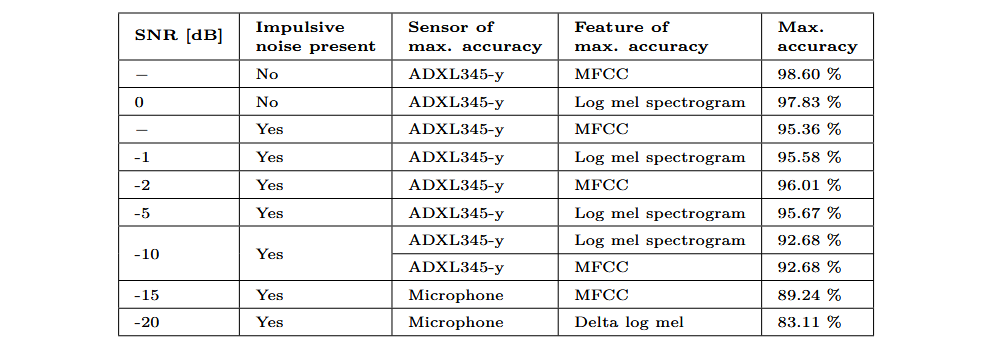
En total, evalué seis atributos individuales: Log-Mel Spectrogram, Delta-Log-Mel Spectrogram, MFCC, RMS, Amplitude Envelope y Windowed Mean. Cada atributo, extraído de un sensor específico, fue utilizado como único parámetro de entrada en el modelo clasificatorio descrito anteriormente. La siguiente tabla muestra los mejores resultados obtenidos en cada conjunto de datos, así como la combinación de sensor y atributo con la que se logró cada resultado.
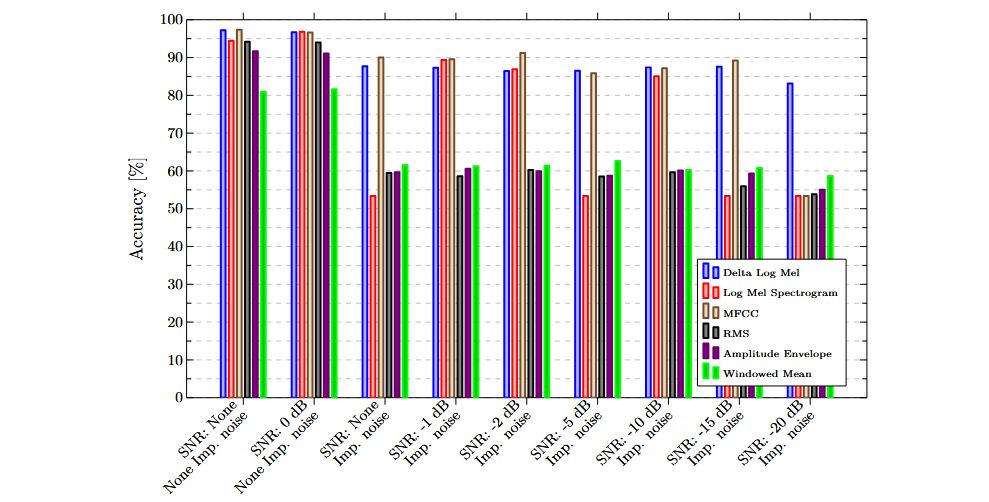
Los siguientes gráficos ilustran los resultados obtenidos con atributos y sensores individuales. En general, los atributos basados en la frecuencia superaron a los puramente temporales, mostrando mayor capacidad para discriminar entre inserciones correctas y fallidas.
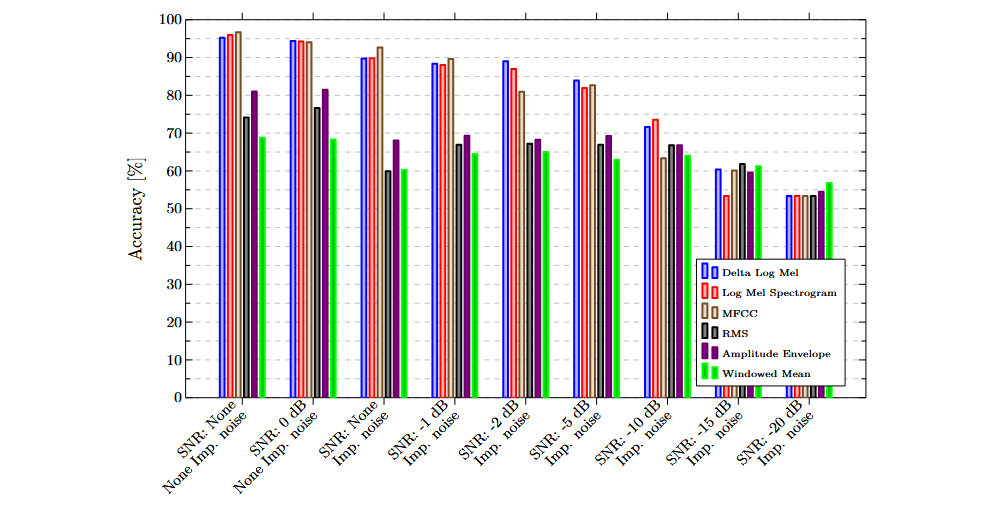
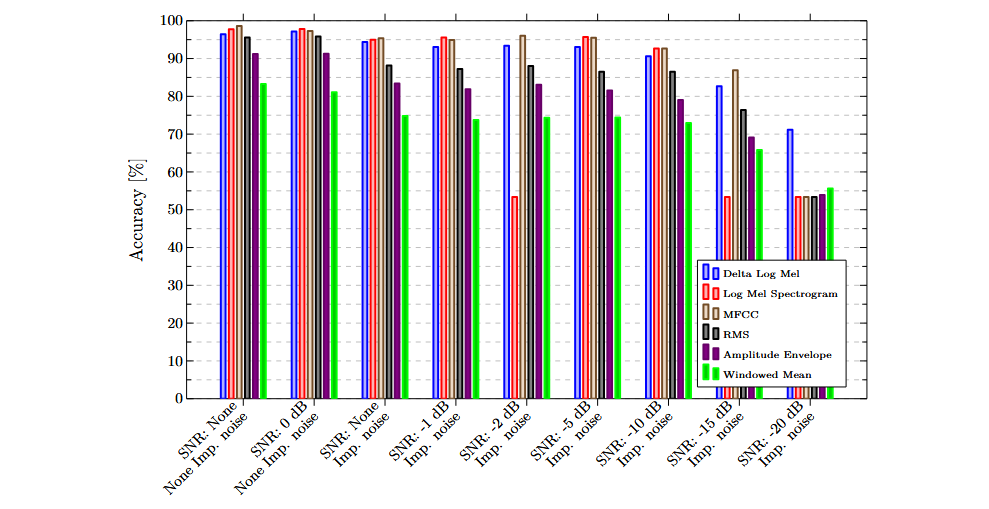
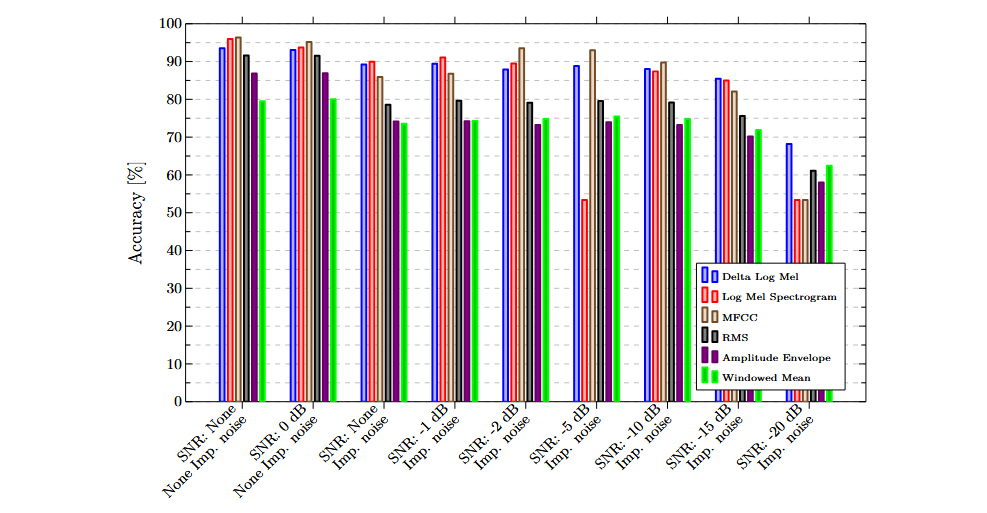
Clasificación multimodal
Tras evaluar la clasificación utilizando atributos individuales, comparé los modelos entrenados con pares de atributos. En total seleccioné 14 combinaciones, empleando los atributos MFCC, Log-Mel y Delta-Log-Mel Spectrogram. Elegí estos atributos porque mostraron resultados significativamente superiores a los de dominio temporal en las evaluaciones individuales. Debido al rendimiento particularmente alto del sensor ADXL345 en el eje y, este fue utilizado en todas las combinaciones. La siguiente tabla muestra las combinaciones seleccionadas y los resultados promedio obtenidos. Los valores de la tabla representan la media de los resultados obtenidos en los nueve conjuntos de datos utilizados.
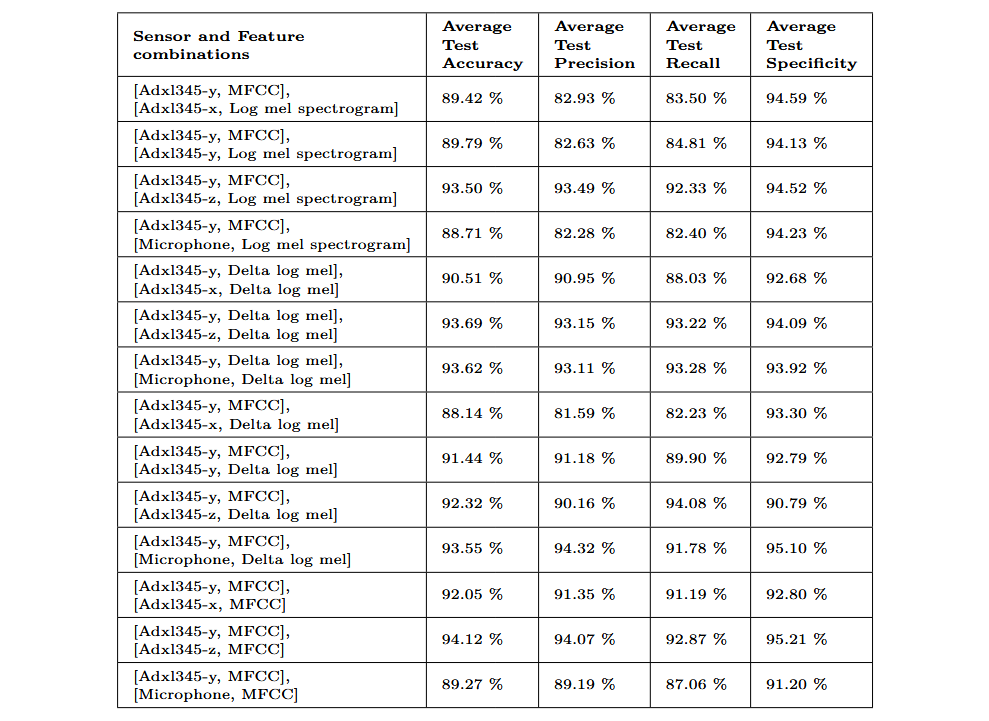
La combinación [[ADXL345-y, MFCC], [ADXL345-z, MFCC]] presenta los valores más altos de accuracy y specificity, siendo por tanto la combinación preferida. El siguiente gráfico muestra los valores obtenidos con esta combinación para cada uno de los conjuntos de datos evaluados. Se observa una mejora notable en comparación con los resultados obtenidos utilizando un solo atributo.
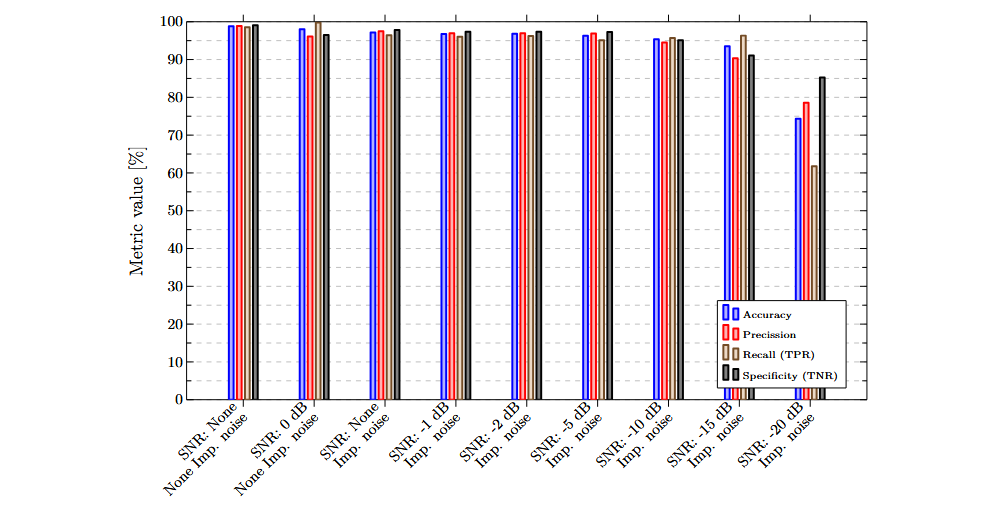
Se puede observar una baja sensibilidad al ruido impulsivo. La diferencia en la accuracy entre el conjunto de datos sin ruido impulsivo y con ruido blanco (SNR = 0 dB), y el conjunto sin ruido blanco y con ruido impulsivo, es de únicamente 0,84 %. La precission y la specificity muestran una mejora del 1,35 % y 1,33 % respectivamente en el conjunto de datos con ruido impulsivo. El recall presenta una disminución del 3,32 %.
Además, el modelo entrenado con esta combinación de atributos es altamente insensible al ruido blanco. Para todos los conjuntos de datos con un SNR de hasta -10 dB, se alcanza una accuracy superior al 95 %. Incluso con un SNR de -15 dB, todas las métricas se mantienen por encima del 90 %.
Validación
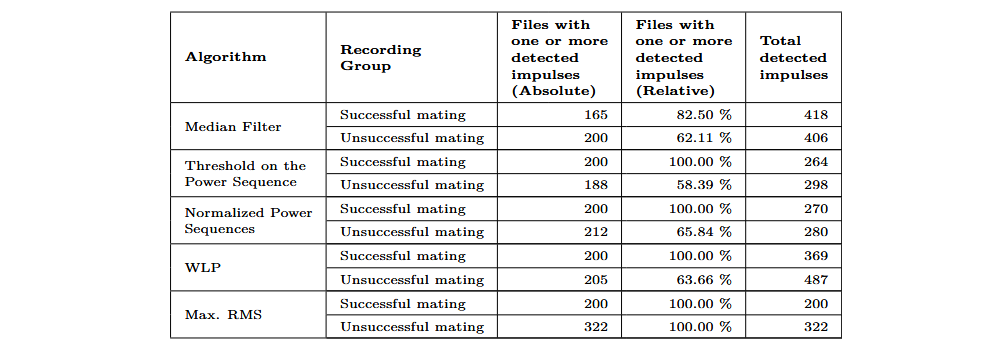
La siguiente tabla muestra los resultados obtenidos con los cinco algoritmos de detección de impulsos aplicados a las grabaciones de evaluación. A excepción del median filter, todos los algoritmos detectaron el 100 % de los impulsos en los intentos de inserción exitosos.
La siguiente tabla presenta la matriz de confusión de validación. El modelo seleccionado utiliza la combinación de atributos [[ADXL345-y, MFCC], [ADXL345-z, MFCC]]. Este modelo fue optimizado con el conjunto de datos sin ruido blanco y con ruido impulsivo. De las 522 grabaciones de validación, cinco fueron clasificadas incorrectamente: dos muestras positivas fueron categorizadas como negativas y tres muestras negativas fueron clasificadas como positivas. De este modo, se obtienen los siguientes resultados:
- Accuracy: 99,04 %
- Recall: 98,51 %
- Precision: 99,00 %
- Specificity: 99,38 %
