Introducción
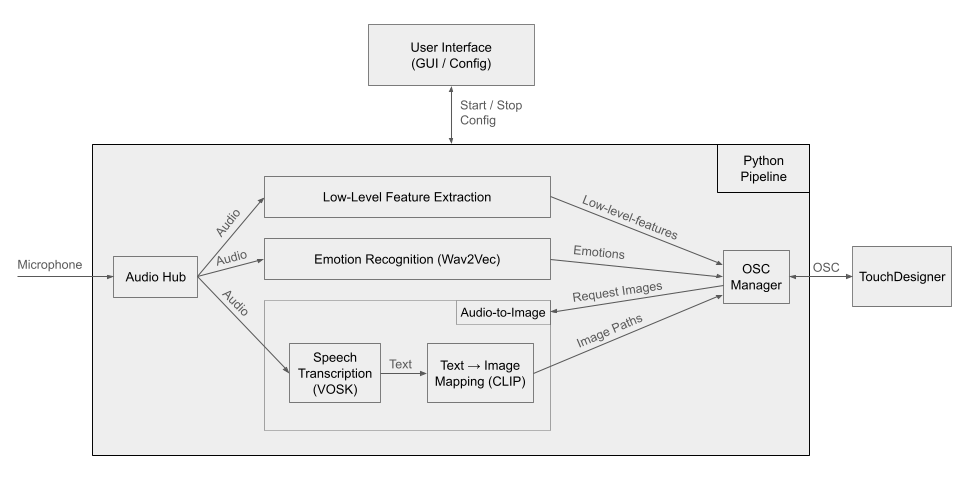
Voice Explosion es un proyecto audiovisual interactivo que convierte la voz humana en una experiencia visual generativa. El sistema combina análisis de audio, reconocimiento de emociones, transcripción del habla y mapeo semántico de imágenes. Estas funciones permiten crear visuales que responden tanto a las características expresivas de la voz como al contenido de las palabras. El proyecto incorpora Python —encargado del procesamiento de audio y los modelos de machine learning— y TouchDesigner, donde se genera la visualización en tiempo real.
El código fuente está disponible en el siguiente repositorio: https://github.com/rj-engineeringde/Voice-Explosion.git
Este es un proyecto personal desarrollado en mi tiempo libre.
Arquitectura
El sistema está compuesto por dos entornos principales: un entorno de procesamiento desarrollado en Python y un entorno de visualización implementado en TouchDesigner. La comunicación entre ambos sistemas se realiza mediante el protocolo Open Sound Control (OSC).
Interfaz gráfica
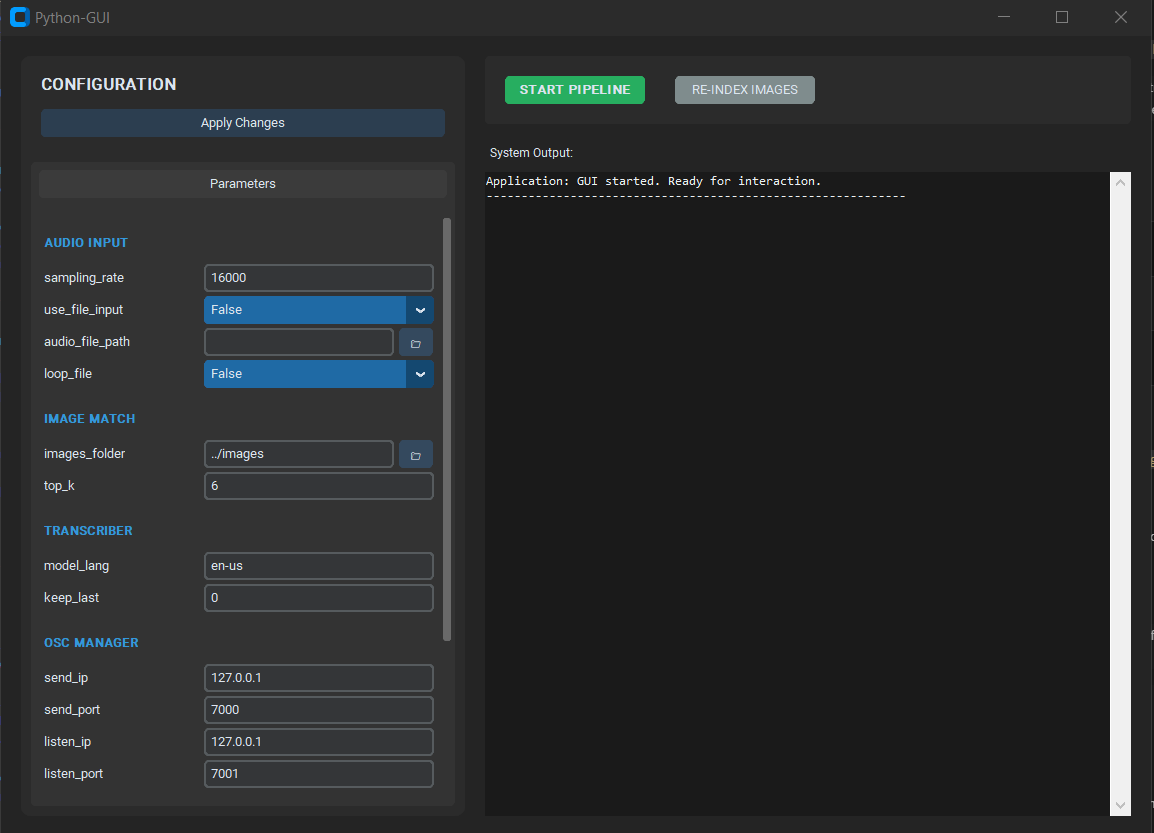
Una interfaz gráfica de usuario actúa como orquestador principal del programa. Esta permite iniciar y detener los distintos procesos y modificar los parámetros de configuración (direcciones IP y puertos para la comunicación OSC, idioma, etc.). La interfaz incorpora una terminal que muestra los errores y mensajes del sistema.
Módulo de procesamiento
El entorno desarrollado en Python se encarga del procesamiento de la señal de audio y de la inferencia de los modelos de machine learning. En esta parte del sistema se realizan la captura de audio, la extracción de características acústicas de bajo nivel, el reconocimiento de emociones en la voz, la transcripción del habla y el mapeo semántico del texto a imágenes. Las emociones y los atributos acústicos de bajo nivel se envían continuamente a TouchDesigner mediante mensajes OSC. Las imágenes, en cambio, solo se procesan y envían cuando han sido previamente solicitadas por TouchDesigner.
Entre las características de bajo nivel utilizadas se encuentran las siguientes:
- Root Mean Square
- Short-Time Energy
- Spectral Centroid
- Spectral Flatness
- Spectral Rolloff
- Pitch
- Harmonics-to-Noise Ratio
- Speech Density
- Detección de actividad / silencio
Además de las características acústicas, el sistema estima continuamente el contenido emocional de la voz. Para ello se utiliza un modelo Wav2vec que analiza la señal de audio y estima tres dimensiones emocionales:
- Arousal (nivel de activación o energía emocional)
- Valence (positividad o negatividad emocional)
- Dominance (grado de control o intensidad emocional)
Estas dimensiones no representan emociones discretas como “feliz” o “triste”, sino un espacio emocional continuo. Los valores obtenidos se utilizan para modificar el comportamiento global de la visualización, por ejemplo la velocidad y el periodo de movimiento de las partículas.
El tercer nivel del análisis se centra en el contenido del lenguaje. La señal de audio se transcribe de manera continua mediante un sistema de reconocimiento de voz (véase VOSK), generando texto a partir del habla. Este texto se utiliza posteriormente para realizar un mapeo semántico hacia imágenes mediante el modelo CLIP de OpenAI. Todos los modelos se ejecutan localmente, lo que permite que el programa funcione sin conexión a internet y garantiza la máxima privacidad del usuario.
TouchDesigner
TouchDesigner constituye la parte visual del sistema. Los parámetros recibidos desde Python se utilizan para controlar el comportamiento de un sistema de partículas, incluyendo su movimiento y dinámica. Además, las imágenes seleccionadas a partir del análisis semántico del texto se emplean como texturas, influyendo en la apariencia y estética global de la visualización.
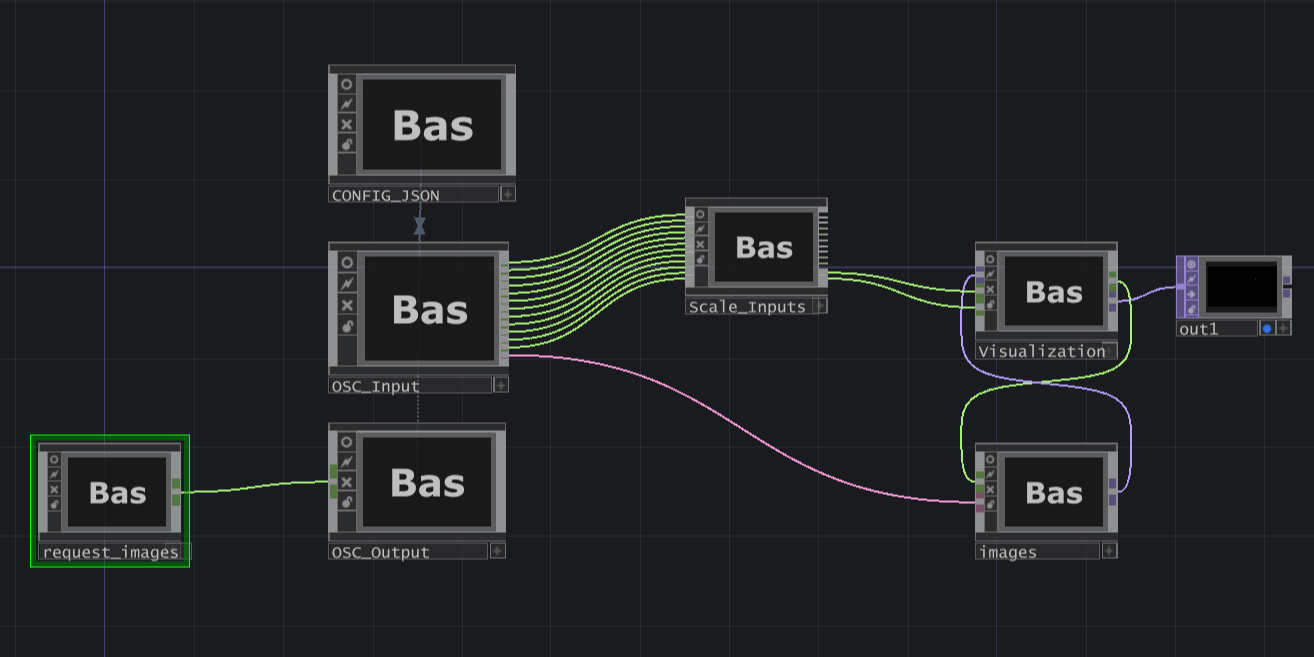
En un principio, la intención era utilizar todos los atributos extraídos en Python. Sin embargo, el uso de solo dos dimensiones emocionales ya permitió obtener resultados satisfactorios. Los atributos restantes se prepararon como parámetros de entrada y podrían emplearse en la visualización en el futuro, si se desea.