Introduction
Voice Explosion is an interactive audiovisual project that transforms the human voice into a generative visual experience. The system combines audio analysis, emotion recognition, speech transcription, and semantic image mapping. These features allow the creation of visuals that respond both to the expressive characteristics of the voice and to the content of the words. The project incorporates Python —responsible for audio processing and machine learning models— and TouchDesigner, where the real-time visualization is generated.
The source code is available in the following repository: https://github.com/rj-engineeringde/Voice-Explosion.git
This is a personal project developed in my free time out of personal interest.
Architecture
The system consists of two main environments: a processing environment developed in Python and a visualization environment implemented in TouchDesigner. Communication between the two systems is carried out via the Open Sound Control (OSC) protocol.
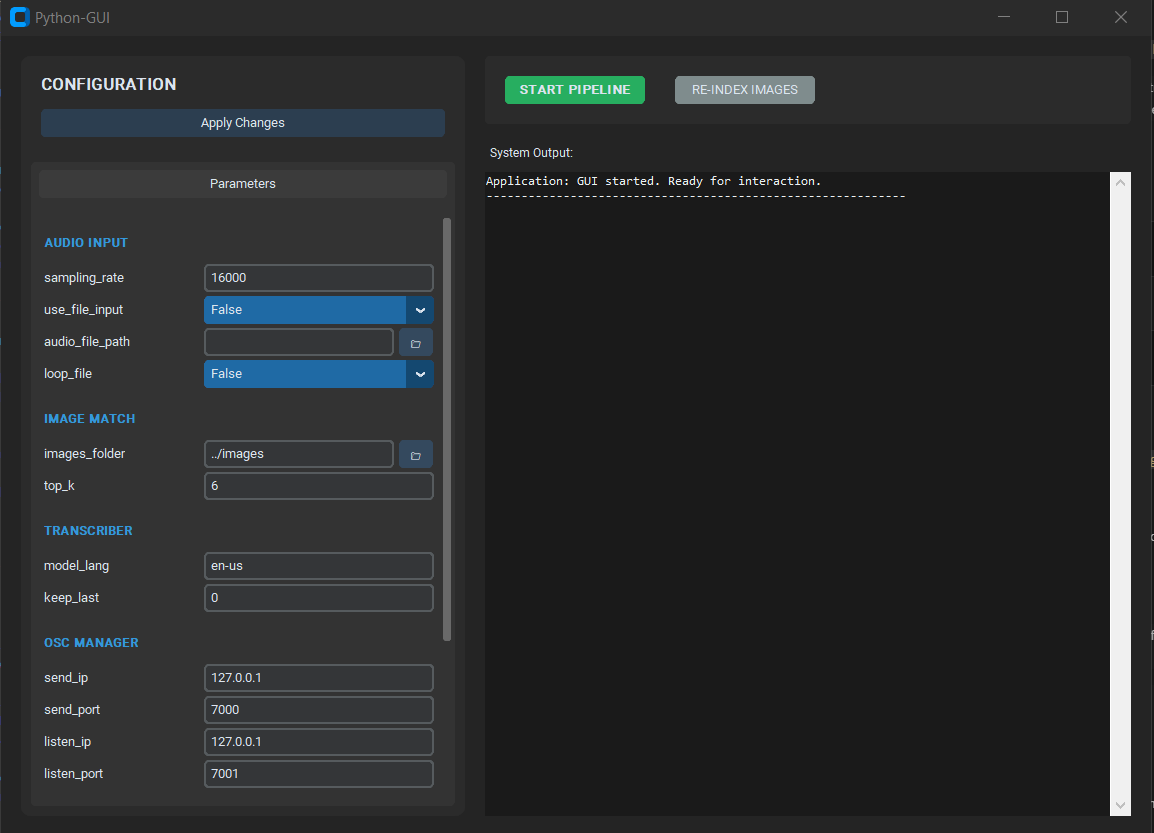
Graphical User Interface
A graphical user interface serves as the main orchestrator of the program. It allows users to start and stop the various processes and modify configuration parameters (IP addresses and ports for OSC communication, language, etc.). The interface also includes a terminal that displays system messages and errors.
Processing Module
The Python environment is responsible for audio signal processing and running the machine learning models. This component of the system handles audio capture, low-level acoustic feature extraction, voice emotion recognition, speech transcription, and the semantic mapping of text to images. Emotions and low-level acoustic attributes are continuously transmitted to TouchDesigner via OSC messages, while images are processed and sent only when specifically requested by TouchDesigner.
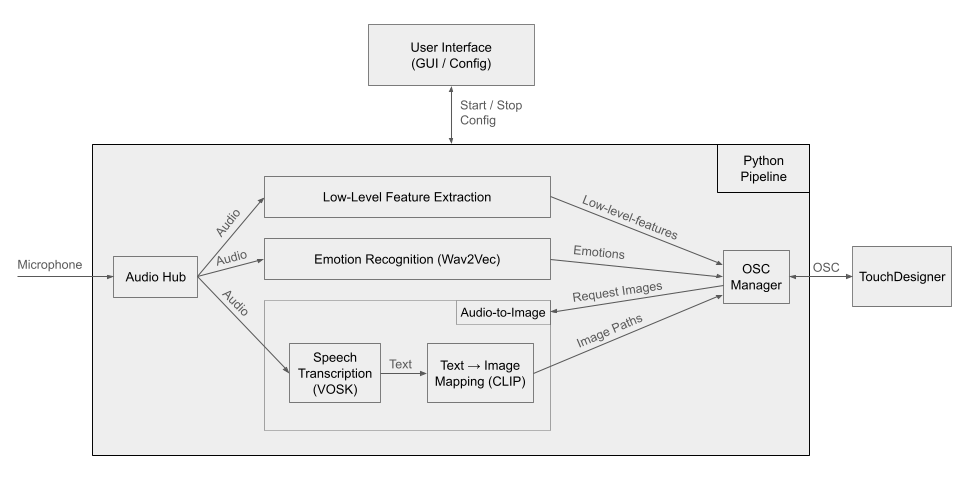
The following low-level features are utilized:
- Root Mean Square
- Short-Time Energy
- Spectral Centroid
- Spectral Flatness
- Spectral Rolloff
- Pitch
- Harmonics-to-Noise Ratio
- Speech Density
- Silence / activity detection
In addition to the acoustic features, the system continuously estimates the emotional content of the voice. For this purpose, a Wav2vec model is used to analyze the audio signal and estimate three emotional dimensions:
- Arousal (level of activation or emotional energy)
- Valence (emotional positivity or negativity)
- Dominance (degree of control or emotional intensity)
These dimensions do not represent discrete emotions such as “happy” or “sad,” but rather a continuous emotional space. The values obtained are used to modify the overall behavior of the visualization, such as the speed and movement period of the particles.
The third level of analysis focuses on language content. The audio signal is continuously transcribed using a speech recognition system (see VOSK), generating text from speech. This text is then used for semantic mapping to images through OpenAI’s CLIP model. All models run locally, allowing the program to operate offline and ensuring maximum user privacy.
TouchDesigner
TouchDesigner forms the visual component of the system. The parameters received from Python are used to control the behavior of a particle system, including its movement and dynamics. Additionally, images selected through the semantic analysis of text are used as textures, influencing the overall appearance and aesthetics of the visualization.
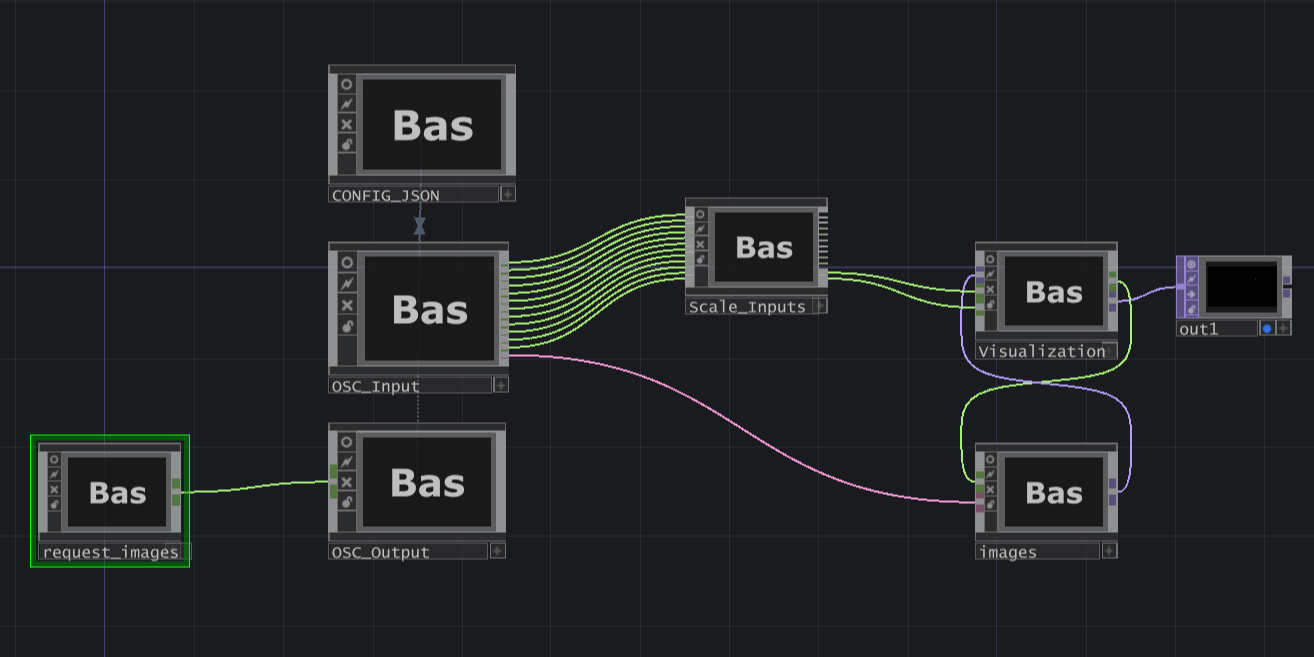
Originally, the intention was to use all the attributes extracted in Python. However, utilizing just two emotional dimensions proved sufficient to achieve satisfactory visuals. The remaining attributes have been prepared as input parameters and could be integrated into the visualization in the future if desired.