Einleitung
Voice Explosion ist eine interaktive audiovisuelle Installation, in der die menschliche Stimme das Verhalten eines generativen Partikelsystems steuert. Das System kombiniert Audioanalyse, Emotionserkennung, Spracherkennung sowie semantisches Mapping von Text zu Bildern. Dadurch entstehen Visualisierungen, die sowohl auf die expressiven Eigenschaften der Stimme als auch auf den inhaltlichen Bedeutungsgehalt der gesprochenen Worte reagieren. Die technische Umsetzung basiert auf Python für die Audioverarbeitung und die Ausführung der Machine-Learning-Modelle sowie auf TouchDesigner für die Echtzeit-Visualisierung.
Der Quellcode ist im folgenden GitHub-Repository verfügbar: https://github.com/rj-engineeringde/Voice-Explosion.git
Dieses persönliche Projekt entstand in meiner Freizeit aus eigenem Interesse.
Architektur
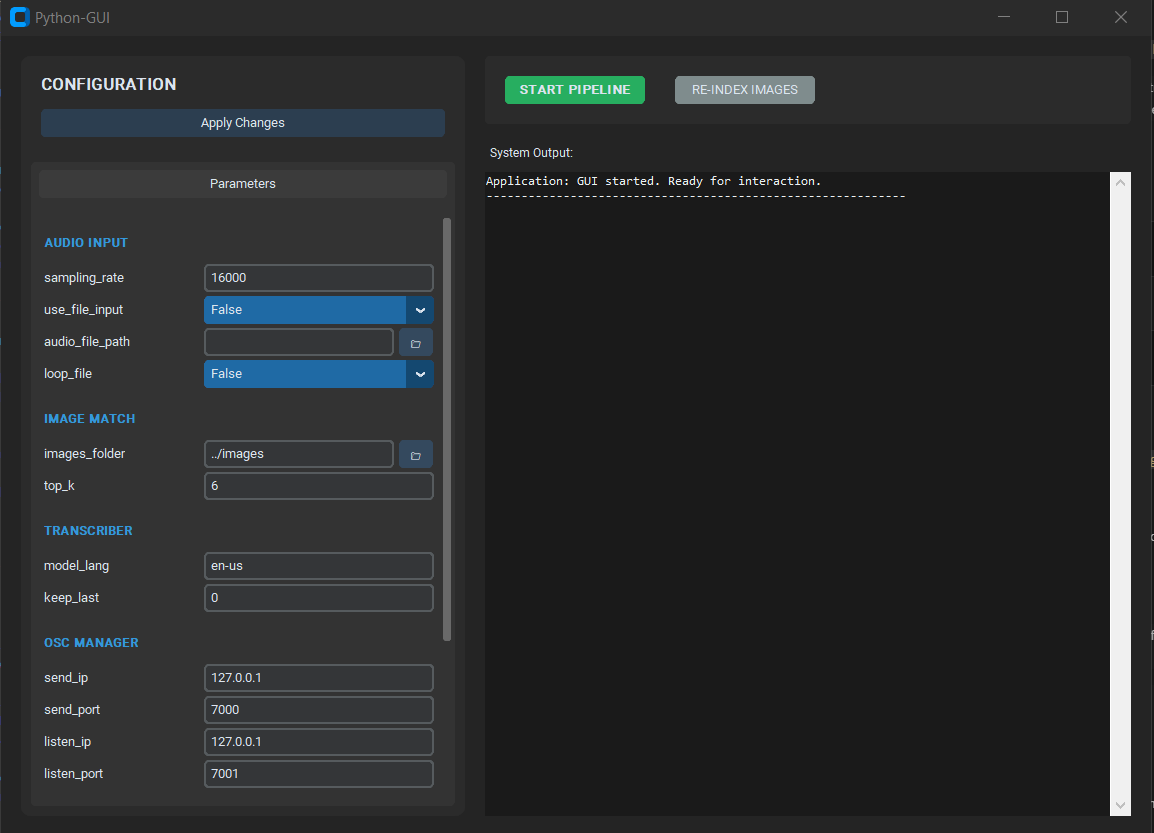
Grafische Benutzeroberfläche
Eine grafische Benutzeroberfläche dient als zentrales Steuerungselement des Programms. Sie ermöglicht das Starten und Beenden der einzelnen Prozesse und erlaubt die Anpassung globaler Einstellungen, wie etwa IP-Adressen und Ports für die OSC-Kommunikation. Zudem verfügt sie über ein Terminal zur Anzeige von System- und Fehlermeldungen.
Verarbeitungsmodul
Die Python-Umgebung übernimmt die Verarbeitung der Audiosignale. Dieser Teil des Systems erledigt die Audioaufnahme, die Extraktion akustischer Merkmale, die Erkennung von Emotionen in der Stimme, die Spracherkennung (Transkription) sowie das semantische Mapping von Text zu Bildern. Die Emotionen und die akustischen Merkmale werden kontinuierlich über OSC-Nachrichten übertragen. Bilder hingegen werden nur verarbeitet und gesendet, wenn sie von TouchDesigner ausdrücklich angefordert werden.
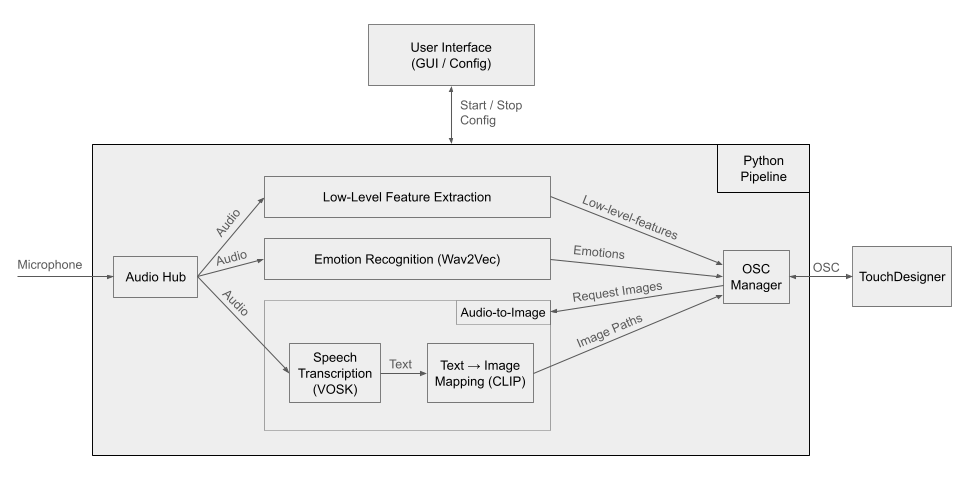
Folgende Audio-Merkmale werden aus dem Roh-Audiosignal extrahiert:
- Root Mean Square
- Short-Time Energy
- Spectral Centroid
- Spectral Flatness
- Spectral Rolloff
- Pitch
- Harmonics-to-Noise Ratio
- Speech Density
- Stille- / Aktivitätserkennung
Zusätzlich zu den akustischen Merkmalen schätzt das System kontinuierlich den emotionalen Gehalt der Stimme. Hierfür wird ein Wav2vec-Modell eingesetzt, das das Audiosignal analysiert und drei emotionale Dimensionen ermittelt:
- Arousal (Aktivierungsgrad bzw. emotionale Energie)
- Valence (emotionale Positivität oder Negativität)
- Dominance (Grad der Kontrolle bzw. emotionale Intensität)
Diese Dimensionen repräsentieren keine diskreten Gefühle wie „glücklich“ oder „traurig“, sondern einen kontinuierlichen emotionalen Raum. Die Werte liegen jeweils zwischen 0 und 1.
Die dritte Analyseebene widmet sich dem sprachlichen Inhalt. Das Audiosignal wird kontinuierlich mit einem Spracherkennungssystem (siehe VOSK) transkribiert, sodass aus der gesprochenen Sprache Text entsteht. Dieser Text wird anschließend über das CLIP-Modell von OpenAI semantisch auf Bilder abgebildet. Alle Modelle laufen lokal, wodurch das Programm vollständig offline funktioniert und die Privatsphäre der Nutzer jederzeit gewährleistet ist.
TouchDesigner
TouchDesigner übernimmt die visuelle Umsetzung. Die über OSC übermittelten Parameter steuern das Verhalten des Partikelsystems, einschließlich Bewegung und Dynamik. Zusätzlich werden die ausgewählten Bilder als Texturen eingesetzt. Sie prägen das Aussehen und die Ästhetik der Visualisierung.
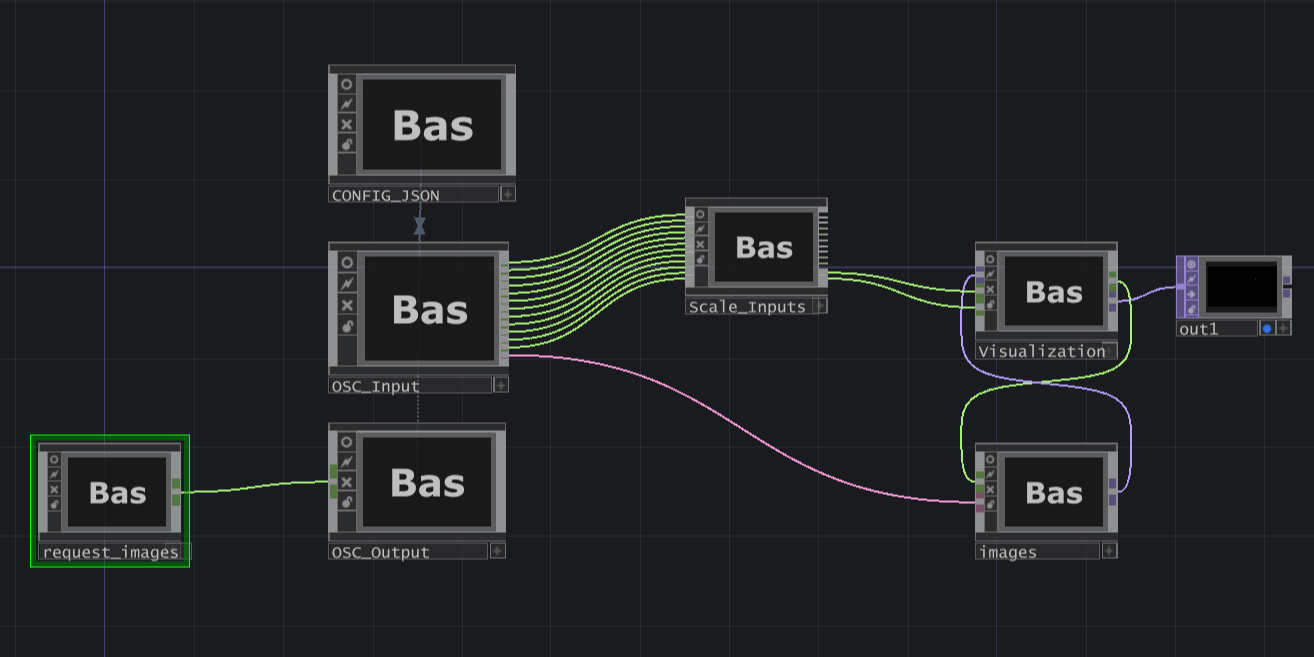
Ursprünglich war beabsichtigt, alle in Python extrahierten Attribute zu verwenden. Es stellte sich jedoch heraus, dass bereits die Nutzung von nur zwei emotionalen Dimensionen ausreichte, um zufriedenstellende Visualisierungen zu erzeugen. Die übrigen Attribute wurden als Eingabeparameter vorbereitet und könnten bei Bedarf zukünftig in die Animation integriert werden.